



Proyecto Access-Biblioteca
OGO_SEP.jpg" width="110" />
CLAVE PRINCIPAL
Posteado en en porClave principal: Proporciona un valor único para cada fila de la tabla y nos sirve de identificador de registros de forma que con esta clave podamos saber sin ningún tipo de equivocación el registro al cual identifica. No podemos definir más de una clave principal, pero podemos tener una clave principal compuesta por más de un campo.
Una clave principal consta de uno o varios campos que identifican de forma exclusiva cada uno de los registros de la tabla. Los valores de los campos de una clave principal no se repetirán a lo largo de la tabla.

ENTIDAD
Posteado en en porEntidad: En una B.D se almacena información de una serie de objetos o elementos. Estos objetos reciben el nombre de entidad. En bases de datos, una entidad es la representación de un objeto o concepto del mundo real que se describe en una base de datos.Una entidad se describe en la estructura de la base de datos empleando un modelo de datos.
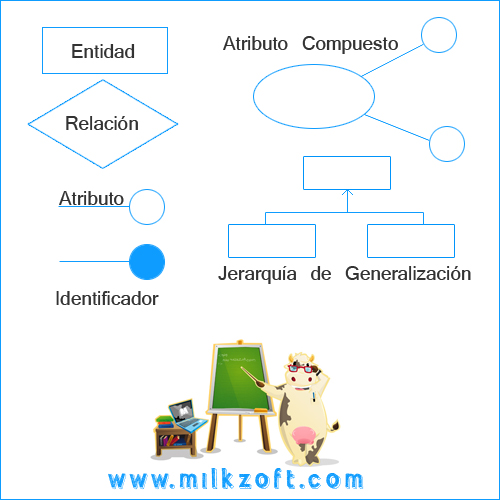
ATRIBUTO
Posteado en en porAtributo:De cada entidad se almacenan una serie de datos que se denominan atributos de la entidad. Pueden ser atributos de una entidad cualquier característica o propiedad de ésta.
RELACION
Posteado en en porRelaciones: En una B.D se almacenan además de las entidades, las relaciones existentes entre ellas.

- Una clave principal identificada con el icono de clave junto al nombre de campo
DIAGRAMA ENTIDAD RELACION
Posteado en en porDiagrama Entidad Relación: Denominado por sus siglas como: E-R; Este modelo representa a la realidad a través de un esquema gráfico empleando los terminología de entidades, que son objetos que existen y son los elementos principales que se identifican en el problema a resolver con el diagramado y se distinguen de otros por sus características particulares denominadas atributos, el enlace que rige la unión de las entidades está representada por la relación del modelo.
Un rectángulo nos representa a las entidades (objetos reales);

Una elipse a los atributos de las entidades (propiedades de estos objetos).

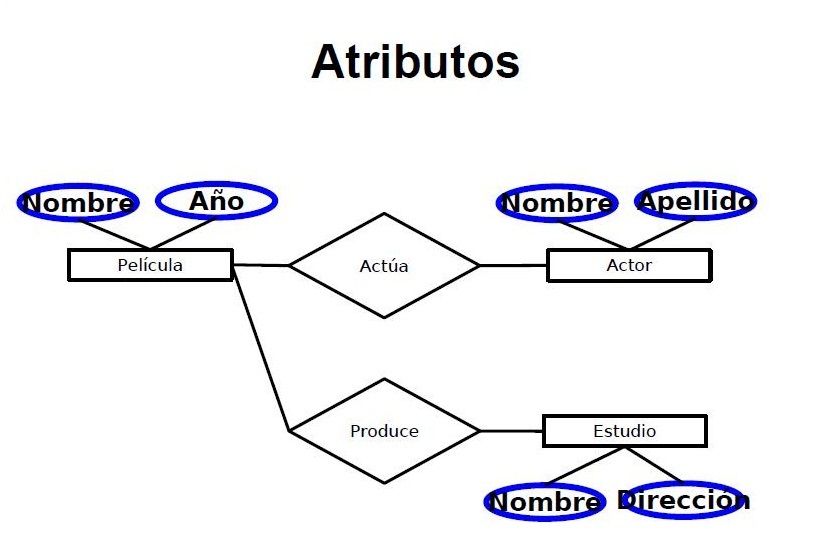
Una etiqueta dentro de un rombo nos indica la relación que existe entre las entidades (enlaces).

Destacando con líneas las uniones de estas y que la llave primaria de una entidad es aquel atributo que se encuentra subrayado.


A continuación mostraremos algunos ejemplos de modelos E-R, considerando las carnalidades que existen entre ellos:
Relación Uno a Uno.
Indicamos con este ejemplo que existe una relación de pertenencia de uno a uno, En este ejemplo, representamos que existe un solo presidente para cada país.

Relación muchos a muchos.
El siguiente ejemplo indica que un cliente puede tener muchas cuentas, pero que una cuenta puede llegar a pertenecer a un solo cliente (Decimos puede, ya que existen cuentas registradas a favor de más de una persona).

CAMPO
Posteado en en porCampo: Lugar físico de almacenamiento destinado a contener información independiente. Los campos son los distintos tipos de datos que componen la tabla, por ejemplo: nombre, apellido, domicilio. La definición de un campo requiere: el nombre del campo, el tipo de campo, el ancho del campo, etc.
El tipo de campo determina la clase de datos que pueden introducirse y las clases de operaciones. Además es un espacio de almacenamiento para un dato en particular. En las bases de datos, un campo es la mínima unidad de información a la que se puede acceder; un campo o un conjunto de ellos forman un registro. En las hojas de cálculo los campos son llamados celdas. La mayoría de los campos tienen atributos asociados a ellos.

Tipos de campos:

- Un valor de campo
- Un campo
- Un registro
·Texto: para introducir cadenas de caracteres hasta un máximo de 255
·Memo: para introducir un texto extenso. Hasta 65.535 caracteres
·Numérico: para introducir números
·Fecha/Hora: para introducir datos en formato fecha u hora
·Moneda: para introducir datos en formato número y con el signo monetario
·Auto numérico: en este tipo de campo, Access numera automáticamente el contenido
·Sí/No: campo lógico. Este tipo de campo es sólo si queremos un contenido del tipo Sí/No, Verdadero/Falso, etc.
·Objeto OLE: para introducir una foto, gráfico, hoja de cálculo, sonido, etc.
·Hipervínculo: podemos definir un enlace a una página Web}
REGISTRO
Posteado en en por
Registro: Conjunto de campos relacionados entre sí que contiene datos referidos a un mismo ente u objeto. Los registros constituyen la información que va contenida en los campos de la tabla, por ejemplo: el nombre del paciente, el apellido del paciente y la dirección de este.
Tipos de registros:
·Registros de longitud fija: todos los campos que lo forman son de longitud fija.
·Registros de longitud variable: uno o varios de los campos que lo integran tiene longitud variable aunque tiene una dimensión máxima que no se sobrepasará.
·Registros de longitud indefinida: la longitud es imposible de determinar. Incluye marcas de final de campo y de fin de registro.




INFORMACION
Posteado en en porInformación: Conjunto de datos organizados de forma coherente. Que constituyen un mensaje que cambia el estado de conocimiento del sujeto o sistema que recibe dicho mensaje.

DATO
Posteado en en porDatos: Es una característica u información referente a un solo individuo u objeto.Es una representación simbólica (numérica, alfabética, algorítmica etc.), un atributo o una característica de una entidad. Los datos son hechos que describen sucesos y entidades. No tienen ninguna información. Puede significar un numero, una letra, o cualquier símbolo que representa una palabra, una cantidad, una medida o una descripción.
El dato no tiene valor semántico (sentido) en sí mismo, pero si recibe un tratamiento (procesamiento) apropiado, se puede utilizar en la realización de cálculos o toma de decisiones. Es de empleo muy común en el ámbito informático y, en general, prácticamente en cualquier disciplina científica.

TIPOS DE RELACIONES EN LAS BASES DE DATOS
Posteado en en porRelaciones "uno a uno"
Estas relaciones entre bases de datos se dan cuando cada campo clave aparece sólo una vez en cada una de las tablas.
Tomando un ejemplo del mundo real, una clara relación de "uno a uno" podría ser, el nombre de cualquier persona y su número de teléfono. Si partimos del supuesto en que cada persona tiene un solo número de teléfono, se podría hablar de una relación "uno a uno".
Garrafalmente, se podría representar de la siguiente manera:

Relaciones de "uno a varios"
El ejemplo del caso anterior (cada persona, un teléfono), si bien es correcto teóricamente, es muy improbable desde el punto de vista de la realidad. Con la gran expansión de los teléfonos, por lo general, cada persona tiene un número de teléfono fijo, y además del teléfono móvil. Debemos tener en cuenta que de el de su casa también tendrá un número de teléfono de empresa, y que quizá también sus móviles estén divididos en ocio y trabajo.
Por ello, debemos tener nuestras bases de datos preparadas para ello. Este tipo de relaciones es conocido como "uno a varios", y se podría representar de la siguiente manera:

Relaciones de "varios con varios"
La última de la relaciones que podemos encontrar es la de "varios con varios". Dado que en la vida las cosas rara vez son sencillas, éste será el tipo de relación que nos encontraremos más a menudo.
Volviendo al tema de los teléfonos, hemos encontrado la manera de relacionar cada una de las personas con sus diversos teléfonos: el de su casa, el de su empresa, el móvil. Pero no será extraño tener en nuestra base de datos diversas personas que trabajen en la misma empresa, por lo que el número de su trabajo será el mismo, o miembros de una misma familia, por lo que compartirán el mismo teléfono de su hogar.
¿Cómo tratar este tipo de relaciones? Si nos limitamos a repetir dicho número de tablas, estaremos creando problemas de redundancia de datos, que a largo plazo lastrarán la rapidez y eficacia de nuestras tablas.
Este tipo de relaciones podría ilustrarse de la siguiente manera:

Como vemos, cada elemento de la base de datos puede relacionarse libremente con uno o varios miembros de las distintas tablas.
En estos casos no hay una regla fija a la que podamos acogernos, pero lo aconsejable es aproximarse lo más posible a la realidad, y no dudar en establecer tablas intermedias que nos ayuden a asociar mejor los datos.
Volviendo al tema de los teléfonos, imaginemos que varias personas de nuestra tabla trabajan en la misma empresa ACME Productions tiene varias líneas, por lo que los números de teléfono de trabajo de estas personas serían varios. ¿Cómo representarlo en nuestra base de datos?
Relaciones de "varios a uno"
Una entidad en A se relaciona exclusivamente con una entidad en B. Pero una entidad en B se puede relacionar con 0 o muchas entidades en A.
BASE DE DATOS
Posteado en en por¿Qué es una base de datos?
Una base de datos (cuya abreviatura es BD) es una entidad en la cual se pueden almacenar datos de manera estructurada, con la menor redundancia posible. Diferentes programas y diferentes usuarios deben poder utilizar estos datos. Por lo tanto, el concepto de base de datos generalmente está relacionado con el de red ya que se debe poder compartir esta información. De allí el término base. “Sistema de información” es el término general utilizado para la estructura global que incluye todos los mecanismos para compartir datos que se han instalado.

¿Por qué utilizar una base de datos?
Una base de datos proporciona a los usuarios el acceso a datos, que pueden visualizar, ingresar o actualizar, en concordancia con los derechos de acceso que se les hayan otorgado. Se convierte más útil a medida que la cantidad de datos almacenados crece.
Una base de datos puede ser local, es decir que puede utilizarla sólo un usuario en un equipo, o puede ser distribuida, es decir que la información se almacena en equipos remotos y se puede acceder a ella a través de una red.
La principal ventaja de utilizar bases de datos es que múltiples usuarios pueden acceder a ellas al mismo tiempo.
Administración de bases de datos
Rápidamente surgió la necesidad de contar con un sistema de administración para controlar tanto los datos como los usuarios. La administración de bases de datos se realiza con un sistema llamado DBMS (Database management system [Sistema de administración de bases de datos]). El DBMS es un conjunto de servicios (aplicaciones de software) para administrar bases de datos, que permite:
- un fácil acceso a los datos
- el acceso a la información por parte de múltiples usuarios
- la manipulación de los datos encontrados en la base de datos (insertar, eliminar, editar)

El DBMS puede dividirse en tres subsistemas:
- El sistema de administración de archivos:
para almacenar información en un medio físico - El DBMS interno:
para ubicar la información en orden - El DBMS externo:
representa la interfaz del usuario
APLICACIÓN DE ESTRUCTURAS DE CONTROL
Posteado en en porPrograma que muestra un menú de opciones y realiza el calculo correspondiente a la elegida, si el usuario lo decea puede repetir otro o el mismo calculo.

Esta es la imagen del programa en ejecución que
muestra el menú y el inicio de mi programa.
 |
| Esta es una imagen de un pequeño texto del código del programa en Pascal. |
9.-HISTORIA DE LA PROGRAMACION
Posteado en en porHISTORIA DE LA PROGRAMACION
Sobre los últimos 50 años, los idiomas que programan han evolucionado del código binario de máquina a herramientas poderosas que crean las abstracciones complejas. Es importante entender por qué los idiomas han evolucionado, y qué capacidades que los idiomas más nuevos nos dan.
"Tan largo como no había máquinas, programar era ningún problema; cuando tuvimos unos pocas computadoras débiles, programar llegó a ser un problema templado y ahora que tenemos las computadoras gigantescas, programar ha llegado a ser un problema igualmente gigantesco. En este sentido que la industria electrónica no ha resuelto un solo problema, tiene sólo los creó - ha creado el problema de usar su producto". [Edsger. W. Dijkstra. "El Programista Humilde" (la Conferencia del Premio de Turing), Comunicaciones del ACM, Vol 15, No. 10 (el octubre 1972).]
E. W. Dijkstra habló estas palabras proféticas casi hace 28 años en su es la conferencia del Premio de Turing. En aquel momento, el 'las computadoras gigantescas él radio de probablemente tenido entre 64 y 128 kilobytes de la memoria verdadera, y a lo más unos pocos mega octetos de artefactos de almacenamiento de acceso directo. Si él pensó que el problema era gigantesco entonces...
Uno de las llaves a programar exitoso son el concepto de la abstracción. La abstracción es la llave a la construcción sistemas complejos de software. Como el tamaño de nuestros problemas crece, la necesidad para la abstracción dramáticamente aumentos. En sistemas sencillos, característica de idiomas usados en el 1950s y '60s, un solo programista podría entender el problema entero, y por lo tanto manipula todas estructuras del programa y datos. Los programistas son hoy incapaces de entender todos los programas y los datos - es apenas demasiado grande. La abstracción se requiere a permitir que el programista para agarrar los conceptos necesarios.
La mayoría de los libros y el reglamento en la historia de programar los idiomas tienden a discutir los idiomas en términos de generaciones. Esto es un arreglo útil para clasificar los idiomas por la edad.
"Tan largo como no había máquinas, programar era ningún problema; cuando tuvimos unos pocas computadoras débiles, programar llegó a ser un problema templado y ahora que tenemos las computadoras gigantescas, programar ha llegado a ser un problema igualmente gigantesco. En este sentido que la industria electrónica no ha resuelto un solo problema, tiene sólo los creó - ha creado el problema de usar su producto". [Edsger. W. Dijkstra. "El Programista Humilde" (la Conferencia del Premio de Turing), Comunicaciones del ACM, Vol 15, No. 10 (el octubre 1972).]
E. W. Dijkstra habló estas palabras proféticas casi hace 28 años en su es la conferencia del Premio de Turing. En aquel momento, el 'las computadoras gigantescas él radio de probablemente tenido entre 64 y 128 kilobytes de la memoria verdadera, y a lo más unos pocos mega octetos de artefactos de almacenamiento de acceso directo. Si él pensó que el problema era gigantesco entonces...
Uno de las llaves a programar exitoso son el concepto de la abstracción. La abstracción es la llave a la construcción sistemas complejos de software. Como el tamaño de nuestros problemas crece, la necesidad para la abstracción dramáticamente aumentos. En sistemas sencillos, característica de idiomas usados en el 1950s y '60s, un solo programista podría entender el problema entero, y por lo tanto manipula todas estructuras del programa y datos. Los programistas son hoy incapaces de entender todos los programas y los datos - es apenas demasiado grande. La abstracción se requiere a permitir que el programista para agarrar los conceptos necesarios.
La mayoría de los libros y el reglamento en la historia de programar los idiomas tienden a discutir los idiomas en términos de generaciones. Esto es un arreglo útil para clasificar los idiomas por la edad.
Primera Generación
Al desarrollarse las primeras computadoras electrónicas, se vio la necesidad de programarlas, es decir, de almacenar en memoria la información sobre la tarea que iban a ejecutar. Las primeras se usaban como calculadoras simples; se les indicaban los pasos de cálculo, uno por uno.
John Von Neumann desarrolló el modelo que lleva su nombre, para describir este concepto de "programa almacenado". En este modelo, se tiene una abstracción de la memoria como un conjunto de celdas, que almacenan simplemente números. Estos números pueden representar dos cosas: los datos, sobre los que va a trabajar el programa; o bien, el programa en sí.
¿Cómo es que describimos un programa como números? Se tenía el problema de representar las acciones que iba a realizar la computadora, y que la memoria, al estar compuesta por switches correspondientes al concepto de bit, solamente nos permitía almacenar números binarios.
Los lenguajes más primitivos fueron los lenguajes de máquina. Esto, ya que el hardware se desarrolló antes del software, y además cualquier software finalmente tiene que expresarse en el lenguaje que maneja el hardware.
La programación en esos momentos era sumamente tediosa, pues el programador tenía que "bajarse" al nivel de la máquina y decirle, paso a pasito, cada punto de la tarea que tenía que realizar. Además, debía expresarlo en forma numérica; y por supuesto, este proceso era propenso a errores, con lo que la productividad del programador era muy limitada. Sin embargo, hay que recordar que en estos momentos, simplemente aún no existía alternativa.
John Von Neumann desarrolló el modelo que lleva su nombre, para describir este concepto de "programa almacenado". En este modelo, se tiene una abstracción de la memoria como un conjunto de celdas, que almacenan simplemente números. Estos números pueden representar dos cosas: los datos, sobre los que va a trabajar el programa; o bien, el programa en sí.
¿Cómo es que describimos un programa como números? Se tenía el problema de representar las acciones que iba a realizar la computadora, y que la memoria, al estar compuesta por switches correspondientes al concepto de bit, solamente nos permitía almacenar números binarios.
Los lenguajes más primitivos fueron los lenguajes de máquina. Esto, ya que el hardware se desarrolló antes del software, y además cualquier software finalmente tiene que expresarse en el lenguaje que maneja el hardware.
La programación en esos momentos era sumamente tediosa, pues el programador tenía que "bajarse" al nivel de la máquina y decirle, paso a pasito, cada punto de la tarea que tenía que realizar. Además, debía expresarlo en forma numérica; y por supuesto, este proceso era propenso a errores, con lo que la productividad del programador era muy limitada. Sin embargo, hay que recordar que en estos momentos, simplemente aún no existía alternativa.
Segunada Generación
El primer gran avance que se dio, como ya se comentó, fue la abstracción dada por el Lenguaje Ensamblador, y con él, el nacimiento de las primeras herramientas automáticas para generar el código máquina. Esto redujo los errores triviales, como podía ser el número que correspondía a una operación, que son sumamente engorrosos y difíciles de detectar, pero fáciles de cometer. Sin embargo, aún aquí es fácil para el programador perderse y cometer errores de lógica, pues debe bajar al nivel de la forma en que trabaja el CPU, y entender bien todo lo que sucede dentro de él.
Tercera Generación
Tercera Generación
Con el desarrollo en los 50s y 60s de algoritmos de más elevado nivel, y el aumento de poder del hardware, empezaron a entrar al uso de computadoras científicos de otras ramas; ellos conocían mucho de Física, Química y otras ramas similares, pero no de Computación, y por supuesto, les era sumamente complicado trabajar con lenguaje Ensamblador en vez de fórmulas. Así, nació el concepto de Lenguaje de Alto Nivel, con el primer compilador de FORTRAN (FORmula TRANslation), que, como su nombre indica, inició como un "simple" esfuerzo de traducir un lenguaje de fórmulas, al lenguaje ensamblador y por consiguiente al lenguaje de máquina. A partir de FORTRAN, se han desarrollado innumerables lenguajes, que siguen el mismo concepto: buscar la mayor abstracción posible, y facilitar la vida al programador, aumentando la productividad, encargándose los compiladores o intérpretes de traducir el lenguaje de alto nivel, al lenguaje de computadora.
Cuarta Generación
Cuarta Generación
Los idiomas de la cuarta generación parecen según las instrucciones a las de la tercera generación. Lo nuevo de estas lenguajes son conceptos como clases, objetos y eventos que permiten soluciones más fáciles y lógicos. Lenguajes como C++, java y C# se llaman lenguajes orientadas al objeto.
Los idiomas modernos, tal como C++ y Java, no sólo permite las abstracciones, pero permite la implementación impuesta de restricciones en abstracciones. La mayoría de los idiomas modernos son objetivas orientado, que permite que mí modele el mundo verdadero que usa mi idioma. Además, puedo limitar el acceso para modelar las restricciones de mundo verdadero en datos. La llave es que usé el término "mundo verdadero." Por la primera vez, yo modelo mi solución en términos del problema. Quiero que mi solución sea orientado de problema, para que la solución refleje el mundo verdadero en términos de estructuras de datos y acceso a los datos. Yo también puedo aplicar directamente y para poder modelar objetos de mundo verdadero usando las clases (en C + + o Java).
Quinta Generación
Los idiomas modernos, tal como C++ y Java, no sólo permite las abstracciones, pero permite la implementación impuesta de restricciones en abstracciones. La mayoría de los idiomas modernos son objetivas orientado, que permite que mí modele el mundo verdadero que usa mi idioma. Además, puedo limitar el acceso para modelar las restricciones de mundo verdadero en datos. La llave es que usé el término "mundo verdadero." Por la primera vez, yo modelo mi solución en términos del problema. Quiero que mi solución sea orientado de problema, para que la solución refleje el mundo verdadero en términos de estructuras de datos y acceso a los datos. Yo también puedo aplicar directamente y para poder modelar objetos de mundo verdadero usando las clases (en C + + o Java).
Quinta Generación
Como la quinta generación están conocidos los Lenguajes de inteligencia artificial. Han sido muy valorados al principio de las noventa - mientras ahora el desarrollo de software toma otras caminos.
Lo que veremos en el futuro es menos dependencia en el idioma, y más en el modelando herramientas, tal como el Unificado Modelando el Idioma (UML). La salida del modelando herramienta producirá mucho de nuestro código para nosotros; en el muy menos, producirá arquitectónico y los modelos del diseño y la estructura de nuestro código. Esto producirá un diseño (y posiblemente código) eso puede ser validado por el cliente antes de completar la implementación y probar. Cuando los problemas diarios que resolvemos llegan a ser más grande, nosotros tenemos cada vez menos tiempo "volver a hacer" el código. Los días de decir, "acabamos de escribir una versión de Beta y el cliente entonces pueden decir nosotros lo que ellos quieren realmente," son pasados. Las organizaciones que fallan de obtener completa y corrige los requisitos de cliente antes de escribir el código saldrá del negocio. ¿Por qué? Porque toma demasiado largo, y cuesta también mucho, para escribir código dos o más vez. Las organizaciones que tienen un compromiso a la comprobación y la validación antes de producir código prosperarán - los otros fallarán.
Pasos importantes de las lenguajes de programación
Lo que veremos en el futuro es menos dependencia en el idioma, y más en el modelando herramientas, tal como el Unificado Modelando el Idioma (UML). La salida del modelando herramienta producirá mucho de nuestro código para nosotros; en el muy menos, producirá arquitectónico y los modelos del diseño y la estructura de nuestro código. Esto producirá un diseño (y posiblemente código) eso puede ser validado por el cliente antes de completar la implementación y probar. Cuando los problemas diarios que resolvemos llegan a ser más grande, nosotros tenemos cada vez menos tiempo "volver a hacer" el código. Los días de decir, "acabamos de escribir una versión de Beta y el cliente entonces pueden decir nosotros lo que ellos quieren realmente," son pasados. Las organizaciones que fallan de obtener completa y corrige los requisitos de cliente antes de escribir el código saldrá del negocio. ¿Por qué? Porque toma demasiado largo, y cuesta también mucho, para escribir código dos o más vez. Las organizaciones que tienen un compromiso a la comprobación y la validación antes de producir código prosperarán - los otros fallarán.
Pasos importantes de las lenguajes de programación

Historia de las lenguajes de programación

8. PSEUDOCODIGO
Posteado en en porPSEUDOCODIGO
Es un lenguaje que se asemeja a los lenguajes de programación en los que se crean software de programación para la PC pero sin el rigor y exactitud que estos tienen a nivel sintáctico; es una forma clara de escribir programas en un lenguaje común o cotidiano.

7.- TIPOS DE DATOS
Posteado en en porTIPOS DE DATOS
El tipo de un dato es el conjunto de valores que puede tomar durante el programa. Si se le intenta dar un valor fuera del conjunto se producirá un error.
La asignación de tipos a los datos tiene dos objetivos principales:
- Por un lado, detectar errores en las operaciones
- Por el otro, determinar cómo ejecutar estas operaciones
Tipos estáticos
Casi todos los tipos de datos son estáticos, la excepción son los punteros y no se tratarán debido a su complejidad.
Casi todos los tipos de datos son estáticos, la excepción son los punteros y no se tratarán debido a su complejidad.
Que un tipo de datos sea estático quiere decir que el tamaño que ocupa en memoria no puede variar durante la ejecución del programa. Es decir, una vez declarada una variable de un tipo determinado, a ésta se le asigna un trozo de memoria fijo, y este trozo no se podrá aumentar ni disminuir.
Tipos dinámicos
Dentro de esta categoría entra solamente el tipo puntero. Este tipo te permite tener un mayor control sobre la gestión de memoria en tus programas. Con ellos puedes manejar el tamaño de tus variables en tiempo de ejecución, o sea, cuando el programa se está ejecutando.
Dentro de esta categoría entra solamente el tipo puntero. Este tipo te permite tener un mayor control sobre la gestión de memoria en tus programas. Con ellos puedes manejar el tamaño de tus variables en tiempo de ejecución, o sea, cuando el programa se está ejecutando.
Los punteros quizás sean el concepto más complejo a la hora de aprender un lenguaje de programación, sobre todo si es el primero que aprendes. Debido a esto, no lo trataremos. Además, lenguajes que están muy de moda (por ejemplo Java) no permiten al programador trabajar con punteros.
Tipos simples
Como su nombre indica son los tipos básicos en Pascal. Son los más sencillos y los más fáciles de aprender. Por todo esto, serán en los que nos centremos.
Como su nombre indica son los tipos básicos en Pascal. Son los más sencillos y los más fáciles de aprender. Por todo esto, serán en los que nos centremos.
Los tipos simples más básicos son: entero, lógico, carácter y real. Y la mayoría de los lenguajes de programación los soportan, no como ocurre con los estructurados que pueden variar de un lenguaje a otro.
El tipo integer (entero)Como ya habrás leído el tipo de datos entero es un tipo simple, y dentro de estos, es ordinal. Al declarar una variable de tipo entero, estás creando una variable numérica que puede tomar valores positivos o negativos, y sin parte decimal.
Este tipo de variables, puedes utilizarlas en asignaciones, comparaciones, expresiones aritméticas, etc. Algunos de los papeles más comunes que desarrollan son:
- Controlar un bucle
- Usarlas como contador, incrementando su valor cuando sucede algo
- Realizar operaciones enteras, es decir, sin parte decimal
- Y muchas más...
A continuación tienes un ejemplo en el que aparecen dos variables enteras. Como puedes ver, en el ejemplo se muestran las dos maneras de declarar una variable de tipo entero:

El tipo de datos lógico es el que te permite usar variables que disponen sólo de dos posibles valores: cierto o falso. Debido a esto, su utilidad salta a la vista, y no es otra que variables de chequeo. Nos sirven para mantener el estado de un objeto mediante dos valores:
- si/no
- cierto/falso
- funciona/no funciona
- on/off
- etc.
Para aclararlo, veamos un ejemplo:

El tipo real (real)
Como ya has visto, Pascal soporta el conjunto entero de números. Pero no es el único, también te permite trabajar con números pertenecientes al conjunto real.
El tipo de datos real es el que se corresponde con los números reales. Este es un tipo importante para los cálculos. Por ejemplo en los estadísticos, ya que se caracterizan por tratar fundamentalmente con valores decimales.
nota: Aunque pueda que estés acostumbrado a escribir con coma los decimales, te advierto que en Pascal y en todos los lenguajes de programación se escribe con un punto. Por ejemplo: 3.1416
A continuación tienes un ejemplo en el que se utiliza el tipo real. En el puedes ver las dos formas de declarar una variable real, y tambíen el uso de una constante real. Por si tienes curiosidad, el resultado de ejecutar el programa compilado es:
El área para un radio de 3.14 es 63.6174

Los tipos char y string (carácter y cadena)
Con el tipo carácter puedes tener objetos que representen una letra, un número, etc. Es decir, puedes usar variables o constantes que representen un valor alfanumérico. Pero ojo, cada variable sólo podrá almacenar un carácter.
Sin embargo, con las cadenas de caracteres (strings) puedes contener en una sóla variable más de un carácter. Por ejemplo, puedes tener en una variable tu nombre.
Veamos cómo se usan ambos tipos en el siguiente ejemplo

Tipos estructurados
Mientras que una variable de un tipo simple sólo referencia a un elemento, los estructurados se refieren a colecciones de elementos.
Mientras que una variable de un tipo simple sólo referencia a un elemento, los estructurados se refieren a colecciones de elementos.
Las colecciones de elementos que aparecen al hablar de tipos estructurados son muy variadas: tenemos colecciones ordenadas que se representan mediante el tipo array, colecciones sin orden mediante el tipo conjunto, e incluso colecciones que contienen otros tipos, son los llamados registros.
Tipos ordinales
Dentro de los tipos simples, los ordinales son los más abundantes. De un tipo se dice que es ordinal porque el conjunto de valores que representa se puede contar, es decir, podemos establecer una relación uno a uno entre sus elementos y el conjunto de los números naturales.
Dentro de los tipos simples, los ordinales son los más abundantes. De un tipo se dice que es ordinal porque el conjunto de valores que representa se puede contar, es decir, podemos establecer una relación uno a uno entre sus elementos y el conjunto de los números naturales.
Dentro de los tipos simples ordinales, los más importantes son:
- El tipo entero (integer)
- El tipo lógico (boolean)
- El tipo carácter (char)
Tipos no-ordinales
Simplificando, podríamos reducir los tipos simples no-ordinales al tipo real. Este tipo nos sirve para declarar variables que pueden tomar valores dentro del conjunto de los números reales.
Simplificando, podríamos reducir los tipos simples no-ordinales al tipo real. Este tipo nos sirve para declarar variables que pueden tomar valores dentro del conjunto de los números reales.
A diferencia de los tipos ordinales, los no-ordinales no se pueden contar. No se puede establecer una relación uno a uno entre ellos y los número naturales. Dicho de otra forma, para que un conjunto se considere ordinal se tiene que poder calcular la posición, el anterior elemento y el siguiente de un elemento cualquiera del conjunto. ¿Cuál es el sucesor de 5.12? Será 5.13, o 5.120, o 5.121,...
Suscribirse a:
Comentarios (Atom)


